Recently one of my colleagues wanted to calculate driving routes and CO2 emissions for car journeys in the UK. He put together a prototype in ModelBuilder and published it as a geoprocessing service to ArcGIS Server so that we could run it from the web.
Although the model worked well, we noticed that it felt sluggish for a web service that was going to be accessed repeatedly, so we started looking at straightforward ways to boost the model’s performance.
The first thing we did was to measure! We looked carefully at which tools in the model were running quickly and which ones weren’t. To do this, we opened up the model for editing in ArcCatalog and from the “Model” menu selected “Run Entire Model”. As each tool in the sequence is executed, its process box is temporarily highlighted red.
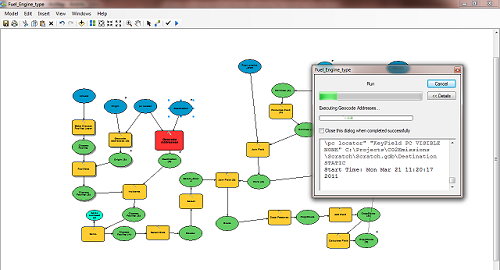
Any tool that stays red for an extended period of time is a possible bottleneck that needs further investigation. This is a great way to visualise where delays in your model are happening. For the more numerically inclined, the number of seconds taken to execute each tool (rounded down to the nearest second) is also shown in the progress box.
Although how you proceed will depend on your individual circumstances, we found two quick wins to speed up our particular model, which made it run about four times faster!
- We used in-memory workspaces to store temporary data
- We reduced the number of tools by replacing entire tool sequences with Python scripts
Let’s look at these in more detail.
Typically, each tool in the model processes some data and writes its output to a feature class in the scratch workspace (a directory on your computer’s hard disk). The next tool in the model reads its input from this location and the cycle repeats.
Writing to the hard disk is much slower than writing to a temporary location in the computer’s memory (RAM), so consider using an in-memory workspace for passing data from one tool to the next.
In-memory workspaces have some important limitations, which are discussed in the articles below:
Intermediate data and the scratch workspace (ArcGIS 9.3, scroll down to see the section on in-memory workspaces)
Using in-memory workspace (ArcGIS 10.0)
In particular, data (e.g. feature classes) written to an in-memory workspace cannot be edited once they have been written. You should also delete in-memory data after you are finished with them, otherwise they can fill up your computer’s RAM until you restart your ArcGIS Desktop client (if running a Desktop model) or your server process is recycled (if running a geoprocessing service), which might not happen for hours. The “Delete” tool can be used to clear an “in_memory” workspace.
Secondly, our model uses a sequence of tools such as “Calculate Field” and “Join Field” to look up CO2 emissions data from a table and calculate an estimate for our car journey. However, we could do this more efficiently by replacing the tool sequence with a single Python script that doesn’t spend a lot of time passing data between different tools.
The following pages have useful information and Python code samples that show you how to wire up a Python script’s inputs and outputs so it can be used as a tool in a ModelBuilder model.
Setting script tool parameters using the arcgisscripting module (ArcGIS 9.3)
Setting script tool parameters using the arcpy module (ArcGIS 10.0)
The general process of performance tuning involves measuring the areas of your model that are slow and making them more efficient (e.g. slow actions might be reading from/writing to disk, using more tools than you need to, using data without attribute indexes, etc)
If you’re interested in learning more, the ArcGIS Resource Center has some general performance tips for geoprocessing services.
For more detailed insights into geoprocessing on Server, there’s a useful video presentation from the 2010 Esri, Inc. Developer Summit:
Building and Optimizing Geoprocessing Services in ArcGIS Server
Happy performance tuning!